Now Available:
For SMBs, Datoin's Customer Churn Apps
Explore
»
Datoin accelerates Machine Learning adoption in your enterprise.
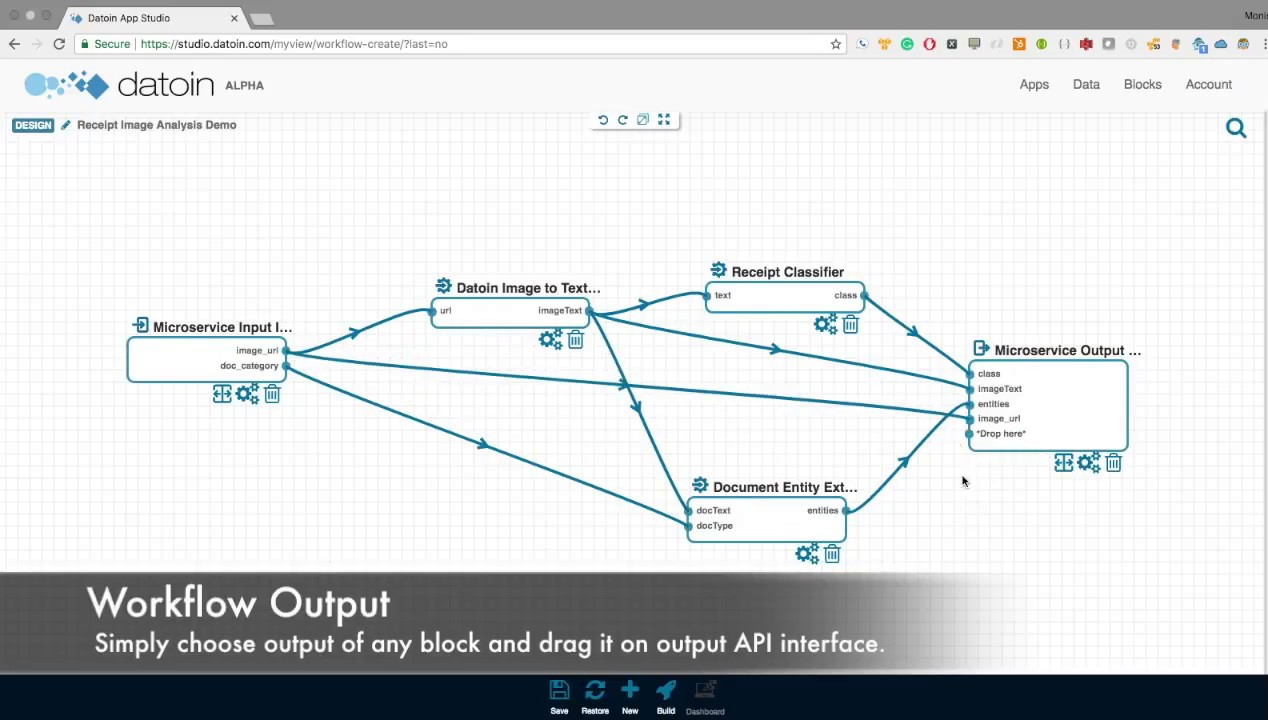
Datoin removes the barrier to entry into Machine Learning using Graphical Interface and No-Code approach.
It is designed to rapidly translate your vision into reality.
Focus on business problems, not technology
Build a Lean Data Science Team
Build in Days, Not Months
Integrates with Enterprise Data
Kick-Start your ML journey by exploring solution templates solving real business problems.
Easily customise existing templates to suit your needs
Accelerate innovation using reusable building blocks
Connect to Datoin ML experts
Building Machine Learning solutions never got this easy!
Works on your on-premise or cloud infrastructure
Integrate data from disparate sources
Measure and control your ML apps
Datoin is built to solve the challenges of enterprise integrations.
Discover the ML opportunities at your enterprise through Datoin.
How do I
empower sales agents to sell better?
How can I solve my
customer onboarding problem?
How to
distribute the workload evenly across month?
Is there a way to
automate my back office workloads?
How do I maintain the
steady cash flow?
How can I
retain customers at risk?